
Мы в Badoo постоянно мониторим свежие технологии и оцениваем, стоит ли использовать их в нашей системе. Одним из таких исследований и хотим поделиться с сообществом. Оно посвящено Loki — системе агрегирования логов.
Loki — это решение для хранения и просмотра логов, также этот стек предоставляет гибкую систему для их анализа и отправки данных в Prometheus. В мае вышло очередное обновление, которое активно продвигают создатели. Нас заинтересовало, что умеет Loki, какие возможности предоставляет и в какой степени может выступать в качестве альтернативы ELK — стека, который мы используем сейчас.
Что такое Loki
Grafana Loki — это набор компонентов для полноценной системы работы с логами. В отличие от других подобных систем Loki основан на идее индексировать только метаданные логов — labels (так же, как и в Prometheus), a сами логи сжимать рядом в отдельные чанки.
Прежде чем перейти к описанию того, что можно делать при помощи Loki, хочу пояснить, что подразумевается под «идеей индексировать только метаданные». Сравним подход Loki и подход к индексированию в традиционных решениях, таких как Elasticsearch, на примере строки из лога nginx:
172.19.0.4 - - [01/Jun/2020:12:05:03 +0000] "GET /purchase?user_id=75146478&item_id=34234 HTTP/1.1" 500 8102 "-" "Stub_Bot/3.0" "0.001"Традиционные системы парсят строку целиком, включая поля с большим количеством уникальных значений user_id и item_id, и сохраняют всё в большие индексы. Преимуществом данного подхода является то, что можно выполнять сложные запросы быстро, так как почти все данные — в индексе. Но за это приходится платить тем, что индекс становится большим, что выливается в требования к памяти. В итоге полнотекстовый индекс логов сопоставим по размеру с самими логами. Для того чтобы по нему быстро искать, индекс должен быть загружен в память. И чем больше логов, тем быстрее индекс увеличивается и тем больше памяти он потребляет.
Подход Loki требует, чтобы из строки были извлечены только необходимые данные, количество значений которых невелико. Таким образом, мы получаем небольшой индекс и можем искать данные, фильтруя их по времени и по проиндексированным полям, а затем сканируя оставшееся регулярными выражениями или поиском подстроки. Процесс кажется не самым быстрым, но Loki разделяет запрос на несколько частей и выполняет их параллельно, обрабатывая большое количество данных за короткое время. Количество шардов и параллельных запросов в них конфигурируется; таким образом, количество данных, которое можно обработать за единицу времени, линейно зависит от количества предоставленных ресурсов.
Этот компромисс между большим быстрым индексом и маленьким индексом с параллельным полным перебором позволяет Loki контролировать стоимость системы. Её можно гибко настраивать и расширять в соответствии с потребностями.
Loki-стек состоит из трёх компонентов: Promtail, Loki, Grafana. Promtail собирает логи, обрабатывает их и отправляет в Loki. Loki их хранит. А Grafana умеет запрашивать данные из Loki и показывать их. Вообще Loki можно использовать не только для хранения логов и поиска по ним. Весь стек даёт большие возможности по обработке и анализу поступающих данных, используя Prometheus way.
Описание процесса установки можно найти здесь.
Поиск по логам
Искать по логам можно в специальном интерфейсе Grafana — Explorer. Для запросов используется язык LogQL, очень похожий на PromQL, использующийся в Prometheus. В принципе, его можно рассматривать как распределённый grep.
Интерфейс поиска выглядит так:
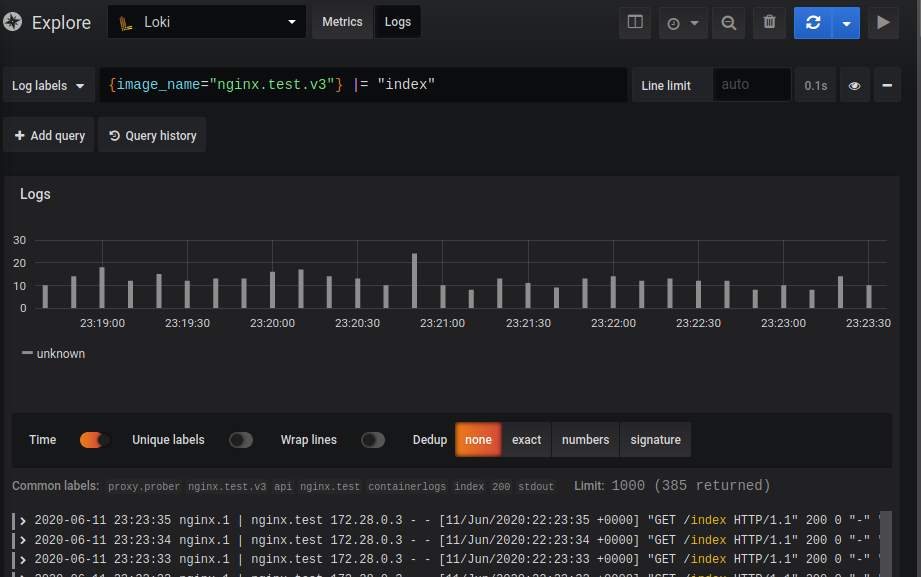
Сам запрос состоит из двух частей: selector и filter. Selector — это поиск по индексированным метаданным (лейблам), которые присвоены логам, а filter — поисковая строка или регэксп, с помощью которого отфильтровываются записи, определённые селектором. В приведенном примере: В фигурных скобках — селектор, все что после — фильтр.
{image_name="nginx.promtail.test"} |= "index"Из-за принципа работы Loki нельзя делать запросы без селектора, но лейблы можно делать сколь угодно общими.
Селектор — это key-value значения в фигурных скобках. Можно комбинировать селекторы и задавать разные условия поиска, используя операторы =, != или регулярные выражения:
{instance=~"kafka-[23]",name!="kafka-dev"}
// Найдёт логи с лейблом instance, имеющие значение kafka-2, kafka-3, и исключит dev Фильтр — это текст или регэксп, который отфильтрует все данные, полученные селектором.
Есть возможность получения ad-hoc-графиков по полученным данным в режиме metrics. Например, можно узнать частоту появления в логах nginx записи, содержащей строку index:
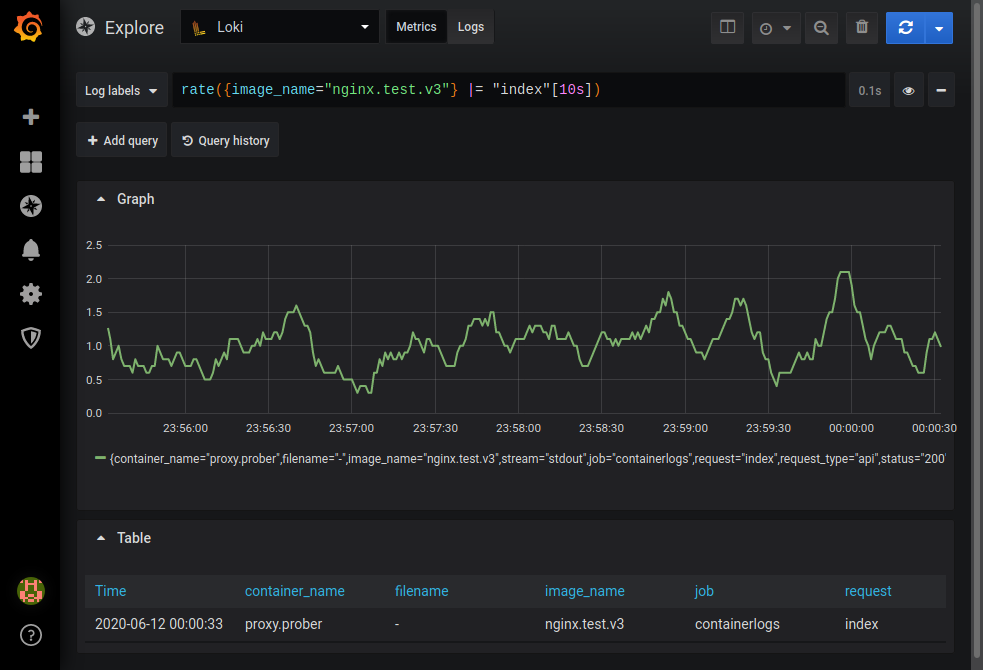
Полное описание возможностей можно найти в документации LogQL.
Парсинг логов
Есть несколько способов собрать логи:
- С помощью Promtail, стандартного компонента стека для сбора логов.
- Напрямую с докер-контейнера при помощи Loki Docker Logging Driver.
- Использовать Fluentd или Fluent Bit, которые умеют отправлять данные в Loki. В отличие от Promtail они имеют готовые парсеры практически для любого вида лога и справляются в том числе с multiline-логами.
Обычно для парсинга используют Promtail. Он делает три вещи:
- Находит источники данных.
- Прикрепляет к ним лейблы.
- Отправляет данные в Loki.
В настоящий момент Promtail может читать логи с локальных файлов и с systemd journal. Он должен быть установлен на каждую машину, с которой собираются логи.
Есть интеграция с Kubernetes: Promtail автоматически через Kubernetes REST API узнаёт состояние кластера и собирает логи с ноды, сервиса или пода, сразу развешивая лейблы на основе метаданных из Kubernetes (имя пода, имя файла и т. д.).
Также можно развешивать лейблы на основе данных из лога при помощи Pipeline. Pipeline Promtail может состоять из четырёх типов стадий. Более подробно — в официальной документации, тут же отмечу некоторые нюансы.
- Parsing stages. Это стадия RegEx и JSON. На этом этапе мы извлекаем данные из логов в так называемую extracted map. Извлекать можно из JSON, просто копируя нужные нам поля в extracted map, или через регулярные выражения (RegEx), где в extracted map “мапятся” named groups. Extracted map представляет собой key-value хранилище, где key — имя поля, а value — его значение из логов.
- Transform stages. У этой стадии есть две опции: transform, где мы задаем правила трансформации, и source — источник данных для трансформации из extracted map. Если в extracted map такого поля нет, то оно будет создано. Таким образом, можно создавать лейблы, которые не основаны на extracted map. На этом этапе мы можем манипулировать данными в extracted map, используя достаточно мощный Golang Template. Кроме того, надо помнить, что extracted map целиком загружается при парсинге, что даёт возможность, например, проверять значение в ней: “{{if .tag}tag value exists{end}}”. Template поддерживает условия, циклы и некоторые строковые функции, такие как Replace и Trim.
- Action stages. На этом этапе можно сделать что-нибудь с извлечённым:
- Создать лейбл из extracted data, который проиндексируется Loki.
- Изменить или установить время события из лога.
- Изменить данные (текст лога), которые уйдут в Loki.
- Создать метрики.
- Filtering stages. Стадия match, на которой можно либо отправить в /dev/null записи, которые нам не нужны, либо направить их на дальнейшую обработку.
Покажу на примере обработки обычных nginx-логов, как можно парсить логи при помощи Promtail.
Для теста возьмём в качестве nginx-proxy модифицированный образ nginx jwilder/nginx-proxy:alpine и небольшой демон, который умеет спрашивать сам себя по HTTP. У демона задано несколько эндпоинтов, на которые он может давать ответы разного размера, с разными HTTP-статусами и с разной задержкой.
Собирать логи будем с докер-контейнеров, которые можно найти по пути /var/lib/docker/containers/<container_id>/<container_id>-json.log
В docker-compose.yml настраиваем Promtail и указываем путь до конфига:
promtail:
image: grafana/promtail:1.4.1
// ...
volumes:
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- promtail-data:/var/lib/promtail/positions
- ${PWD}/promtail/docker.yml:/etc/promtail/promtail.yml
command:
- '-config.file=/etc/promtail/promtail.yml'
// ...
Добавляем в promtail.yml путь до логов (в конфиге есть опция «docker», которая делает то же самое одной строчкой, но это было бы не так наглядно):
scrape_configs:
- job_name: containers
static_configs:
labels:
job: containerlogs
__path__: /var/lib/docker/containers/*/*log # for linux onlyПри включении такой конфигурации в Loki будут попадать логи со всех контейнеров. Чтобы этого избежать, меняем настройки тестового nginx в docker-compose.yml — добавляем логирование поле tag:
proxy:
image: nginx.test.v3
//…
logging:
driver: "json-file"
options:
tag: "{{.ImageName}}|{{.Name}}"Правим promtail.yml и настраиваем Pipeline. На вход попадают логи следующего вида:
{"log":"\u001b[0;33;1mnginx.1 | \u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] \"GET /api/index HTTP/1.1\" 200 0 \"-\" \"Stub_Bot/0.1\" \"0.096\"\n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.66740443Z"}
{"log":"\u001b[0;33;1mnginx.1 | \u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] \"GET /200 HTTP/1.1\" 200 0 \"-\" \"Stub_Bot/0.1\" \"0.000\"\n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.702925272Z"}Pipeline stage:
- json:
expressions:
stream: stream
attrs: attrs
tag: attrs.tagИзвлекаем из входящего JSON поля stream, attrs, attrs.tag (если они есть) и кладём их в extracted map.
- regex:
expression: ^(?P<image_name>([^|]+))\|(?P<container_name>([^|]+))$
source: "tag"Если удалось положить поле tag в extracted map, то при помощи регэкспа извлекаем имена образа и контейнера.
- labels:
image_name:
container_name:Назначаем лейблы. Если в extracted data будут обнаружены ключи image_name и container_name, то их значения будут присвоены соотвестующим лейблам.
- match:
selector: '{job="docker",container_name="",image_name=""}'
action: dropОтбрасываем все логи, у которых не обнаружены установленные labels image_name и container_name.
- match:
selector: '{image_name="nginx.promtail.test"}'
stages:
- json:
expressions:
row: logДля всех логов, у которых image_name равен nginx.promtail.test, извлекаем из исходного лога поле log и кладём его в extracted map с ключом row.
- regex:
# suppress forego colors
expression: .+nginx.+\|.+\[0m(?P<virtual_host>[a-z_\.-]+) +(?P<nginxlog>.+)
source: logrowОчищаем входную строку регулярными выражениями и вытаскиваем nginx virtual host и строку лога nginx.
- regex:
source: nginxlog
expression: ^(?P<ip>[\w\.]+) - (?P<user>[^ ]*) \[(?P<timestamp>[^ ]+).*\] "(?P<method>[^ ]*) (?P<request_url>[^ ]*) (?P<request_http_protocol>[^ ]*)" (?P<status>[\d]+) (?P<bytes_out>[\d]+) "(?P<http_referer>[^"]*)" "(?P<user_agent>[^"]*)"( "(?P<response_time>[\d\.]+)")?Парсим nginx-лог регулярными выражениями.
- regex:
source: request_url
expression: ^.+\.(?P<static_type>jpg|jpeg|gif|png|ico|css|zip|tgz|gz|rar|bz2|pdf|txt|tar|wav|bmp|rtf|js|flv|swf|html|htm)$
- regex:
source: request_url
expression: ^/photo/(?P<photo>[^/\?\.]+).*$
- regex:
source: request_url
expression: ^/api/(?P<api_request>[^/\?\.]+).*$Разбираем request_url. С помощью регэкспа определяем назначение запроса: к статике, к фоткам, к API и устанавливаем в extracted map соответствующий ключ.
- template:
source: request_type
template: "{{if .photo}}photo{{else if .static_type}}static{{else if .api_request}}api{{else}}other{{end}}"При помощи условных операторов в Template проверяем установленные поля в extracted map и устанавливаем для поля request_type нужные значения: photo, static, API. Назначаем other, если не удалось. Теперь request_type содержит тип запроса.
- labels:
api_request:
virtual_host:
request_type:
status:Устанавливаем лейблы api_request, virtual_host, request_type и статус (HTTP status) на основании того, что удалось положить в extracted map.
- output:
source: nginx_log_rowМеняем output. Теперь в Loki уходит очищенный nginx-лог из extracted map.
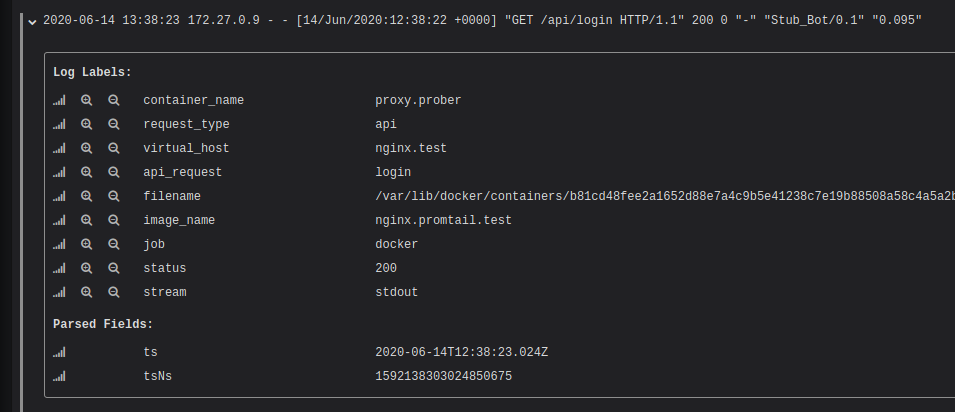
После запуска приведённого конфига можно увидеть, что каждой записи присвоены метки на основе данных из лога.
Нужно иметь в виду, что извлечение меток с большим количеством значений (cardinality) может существенно замедлить работу Loki. То есть не стоит помещать в индекс, например, user_id. Подробнее об этом читайте в статье “How labels in Loki can make log queries faster and easier”. Но это не значит, что нельзя искать по user_id без индексов. Нужно использовать фильтры при поиске («грепать» по данным), а индекс здесь выступает как идентификатор потока.
Визуализация логов
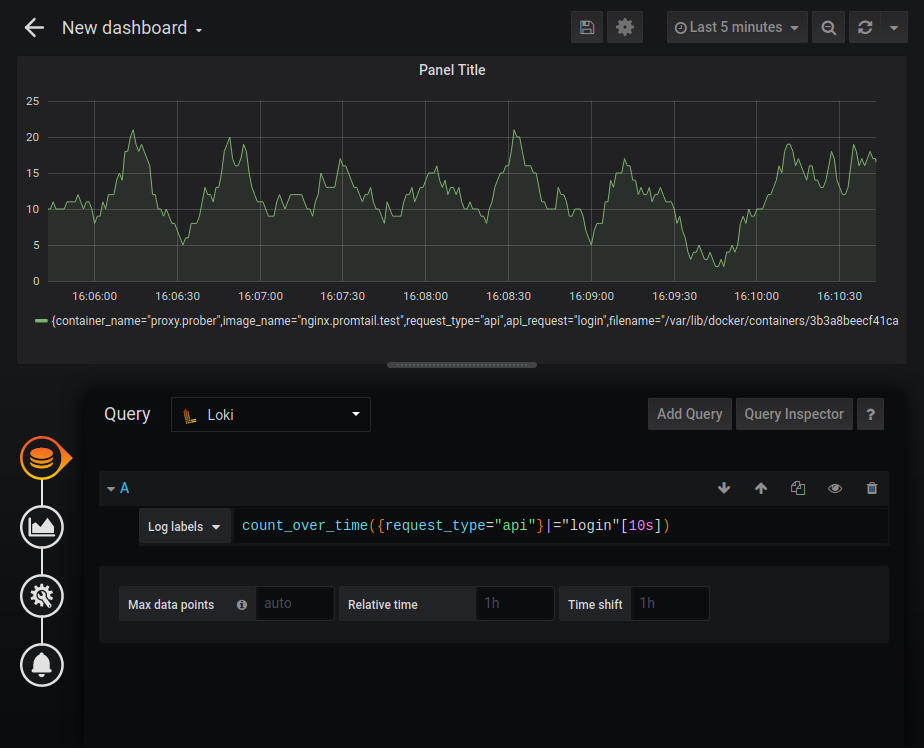
Loki может выступать в роли источника данных для графиков Grafana, используя LogQL. Поддерживаются следующие функции:
- rate — количество записей в секунду;
- count over time — количество записей в заданном диапазоне.
Ещё присутствуют агрегирующие функции Sum, Avg и другие. Можно строить достаточно сложные графики, например график количества HTTP-ошибок:
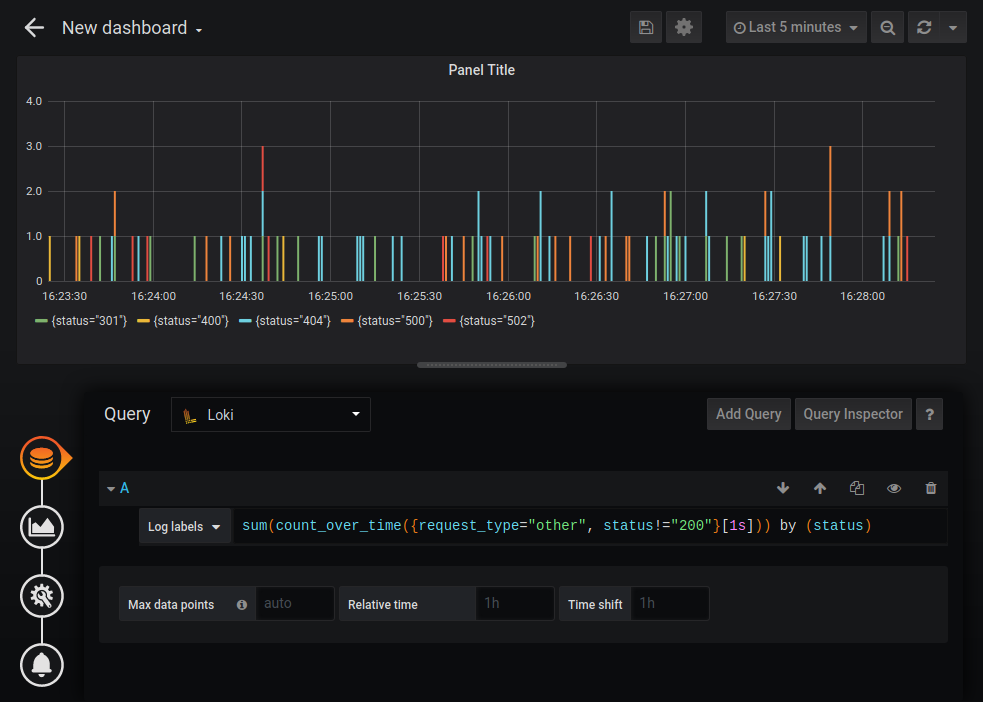
Стандартный data source Loki несколько урезан по функциональности по сравнению с data source Prometheus (например, нельзя изменить легенду), но Loki можно подключить как источник с типом Prometheus. Я не уверен, что это документированное поведение, но, судя по ответу разработчиков “How to configure Loki as Prometheus datasource? · Issue #1222 · grafana/loki”, например, это вполне законно, и Loki полностью совместим с PromQL.
Добавляем Loki как data source с типом Prometheus и дописываем URL /loki:
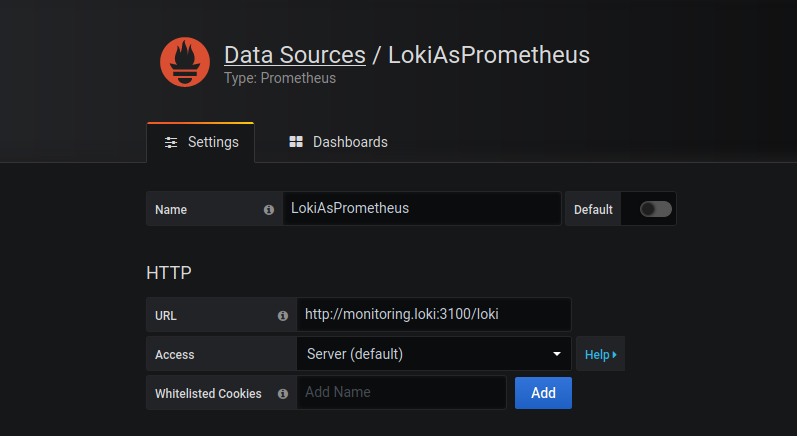
И можно делать графики, как в том случае, если бы мы работали с метриками из Prometheus:
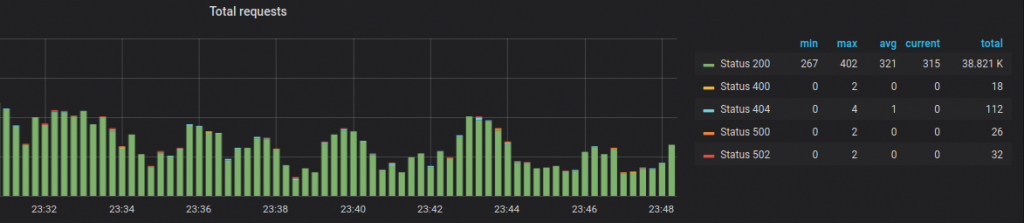
Я думаю, что расхождение в функциональности временное и разработчики в будущем это поправят.
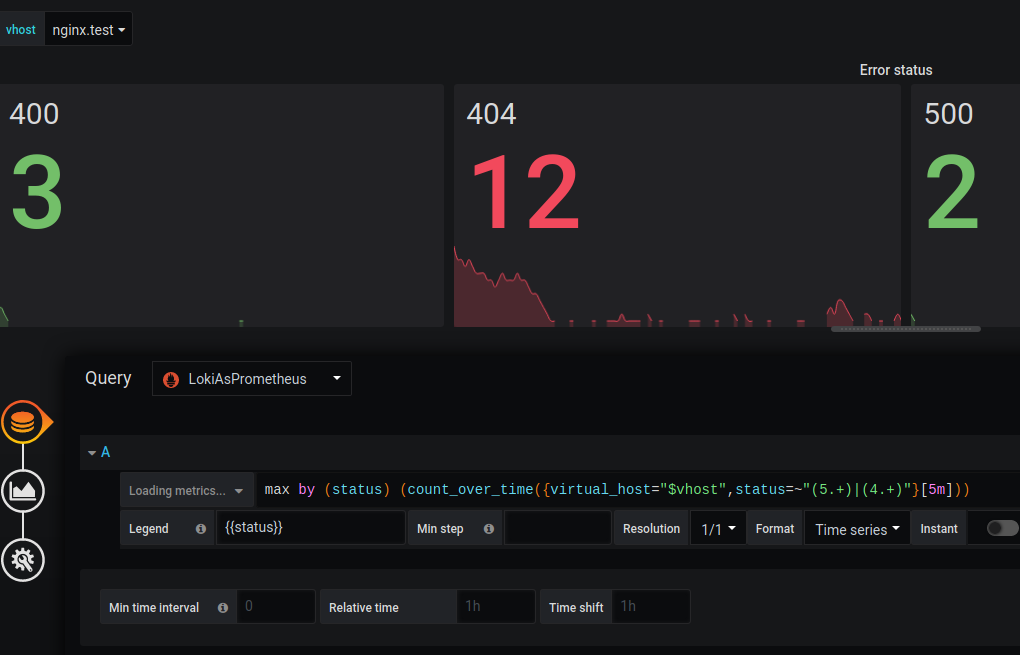
Метрики
В Loki доступны возможность извлечения числовых метрик из логов и отправка их в Prometheus. Например, в логе nginx присутствует количество байтов на ответ, а также, при определённой модификации стандартного формата лога, и время в секундах, которое потребовалось на ответ. Эти данные можно извлечь и отправить в Prometheus.
Добавляем ещё одну секцию в promtail.yml:
- match:
selector: '{request_type="api"}'
stages:
- metrics:
http_nginx_response_time:
type: Histogram
description: "response time ms"
source: response_time
config:
buckets: [0.010,0.050,0.100,0.200,0.500,1.0]
- match:
selector: '{request_type=~"static|photo"}'
stages:
- metrics:
http_nginx_response_bytes_sum:
type: Counter
description: "response bytes sum"
source: bytes_out
config:
action: add
http_nginx_response_bytes_count:
type: Counter
description: "response bytes count"
source: bytes_out
config:
action: incОпция позволяет определять и обновлять метрики на основе данных из extracted map. Эти метрики не отправляются в Loki — они появляются в Promtail /metrics endpoint. Prometheus должен быть сконфигурирован таким образом, чтобы получить данные, полученные на этой стадии. В приведённом примере для request_type=“api” мы собираем метрику-гистограмму. С этим типом метрик удобно получать перцентили. Для статики и фото мы собираем сумму байтов и количество строк, в которых мы получили байты, чтобы вычислить среднее значение.
Более подробно о метриках читайте здесь.
Открываем порт на Promtail:
promtail:
image: grafana/promtail:1.4.1
container_name: monitoring.promtail
expose:
- 9080
ports:
- "9080:9080"Убеждаемся, что метрики с префиксом promtail_custom появились:
Настраиваем Prometheus. Добавляем job promtail:
- job_name: 'promtail'
scrape_interval: 10s
static_configs:
- targets: ['promtail:9080']И рисуем график:
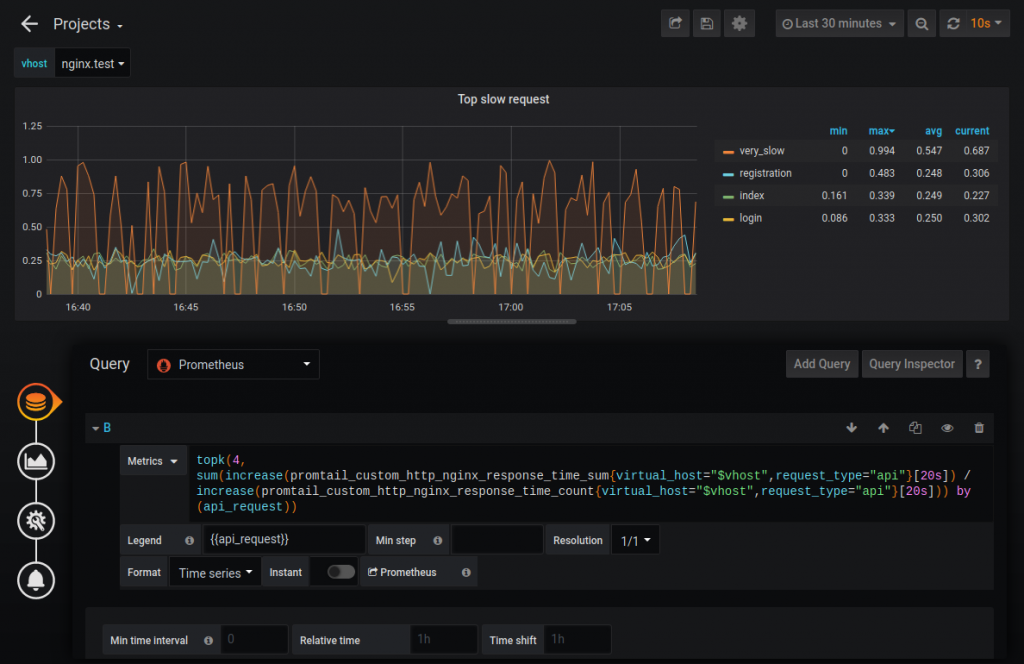
Таким образом можно узнать, например, четыре самых медленных запроса. Также на данные метрики можно настроить мониторинг.
Масштабирование
Loki может быть как в одиночном режиме (single binary mode), так и в шардируемом (horizontally-scalable mode). Во втором случае он может сохранять данные в облако, причём чанки и индекс хранятся отдельно. В версии 1.5 реализована возможность хранения в одном месте, но пока не рекомендуется использовать её в продакшене.
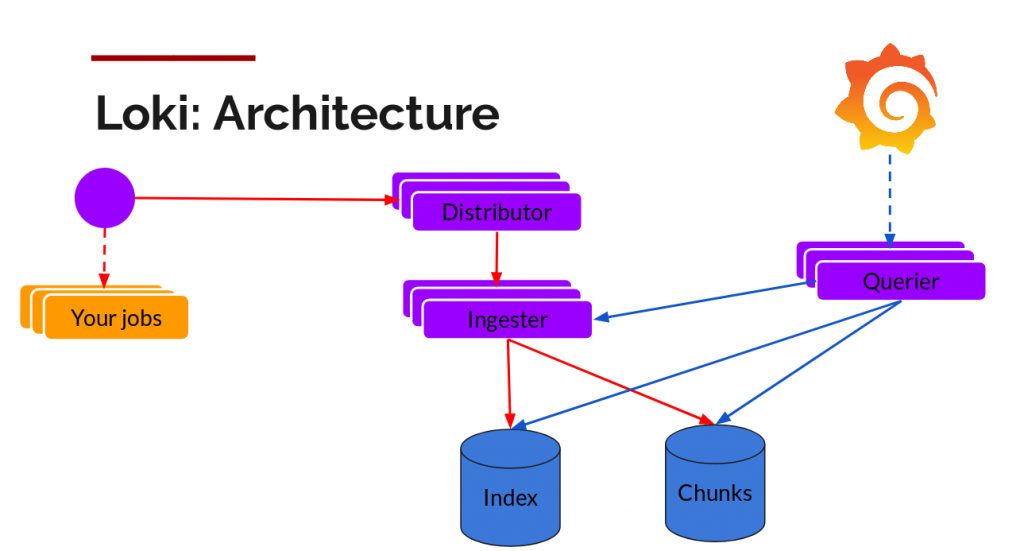
Чанки можно хранить в S3-совместимом хранилище, для хранения индексов — использовать горизонтально масштабируемые базы данных: Cassandra, BigTable или DynamoDB. Другие части Loki — Distributors (для записи) и Querier (для запросов) — stateless и также масштабируются горизонтально.
На конференции DevOpsDays Vancouver 2019 один из участников Callum Styan озвучил, что с Loki его проект имеет петабайты логов с индексом меньше 1% от общего размера: “How Loki Correlates Metrics and Logs — And Saves You Money”.
Сравнение Loki и ELK
Размер индекса
Для тестирования получаемого размера индекса я взял логи с контейнера nginx, для которого настраивался Pipeline, приведённый выше. Файл с логами содержал 406 624 строки суммарным объёмом 109 Мб. Генерировались логи в течение часа, примерно по 100 записей в секунду.
Пример двух строк из лога:

При индексации ELK это дало размер индекса 30,3 Мб:
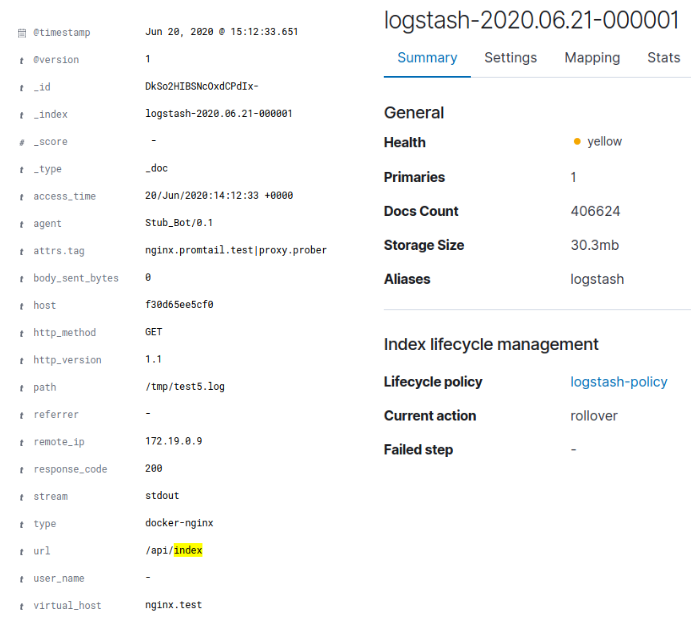
В случае с Loki это дало примерно 128 Кб индекса и примерно 3,8 Мб данных в чанках. Стоит отметить, что лог был искусственно сгенерирован и не отличался большим разнообразием данных. Простой gzip на исходном докеровском JSON-логе с данными давал компрессию 95,4%, а с учётом того, что в сам Loki посылался только очищенный nginx-лог, то сжатие до 4 Мб объяснимо. Суммарное количество уникальных значений для лейблов Loki было 35, что объясняет небольшой размер индекса. Для ELK лог также очищался. Таким образом, Loki сжал исходные данные на 96%, а ELK — на 70%.
Потребление памяти
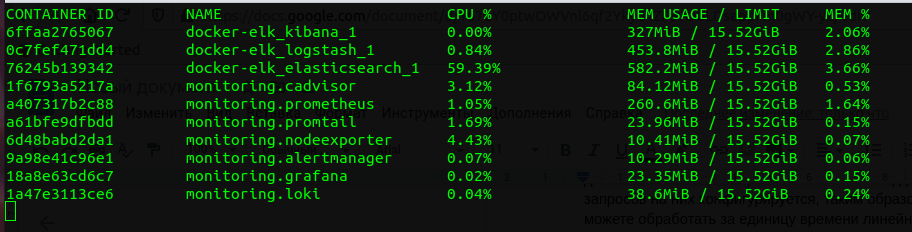
Если сравнивать весь стек Prometheus и ELK, то Loki «ест» в несколько раз меньше. Понятно, что сервис на Go потребляет меньше, чем сервис на Java, и сравнение размера JVM Heap Elasticsearch и выделенной памяти для Loki некорректно, но тем не менее стоит отметить, что Loki использует гораздо меньше памяти. Его преимущество по CPU не так очевидно, но также присутствует.
Скорость
Loki быстрее «пожирает» логи. Скорость зависит от многих факторов — что за логи, как изощрённо мы их парсим, сеть, диск и т. д. — но она однозначно выше, чем у ELK (в моём тесте — примерно в два раза). Объясняется это тем, что Loki кладёт гораздо меньше данных в индекс и, соответственно, меньше времени тратит на индексирование. Со скоростью поиска при этом ситуация обратная: Loki ощутимо притормаживает на данных размером более нескольких гигабайтов, у ELK же скорость поиска от размера данных не зависит.
Поиск по логам
Loki существенно уступает ELK по возможностям поиска по логам. Grep с регулярными выражениями — это сильная вещь, но он уступает взрослой базе данных. Отсутствие range-запросов, агрегация только по лейблам, невозможность искать без лейблов — всё это ограничивает нас в поисках интересующей информации в Loki. Это не подразумевает, что с помощью Loki ничего нельзя найти, но определяет флоу работы с логами, когда вы сначала находите проблему на графиках Prometheus, а потом по этим лейблам ищете, что случилось в логах.
Интерфейс
Во-первых, это красиво (извините, не мог удержаться). Grafana имеет приятный глазу интерфейс, но Kibana гораздо более функциональна.
Плюсы и минусы Loki
Из плюсов можно отметить, что Loki интегрируется с Prometheus, соответственно, метрики и алертинг мы получаем из коробки. Он удобен для сбора логов и их хранения с Kubernetes Pods, так как имеет унаследованный от Prometheus service discovery и автоматически навешивает лейблы.
Из минусов — слабая документация. Некоторые вещи, например особенности и возможности Promtail, я обнаружил только в процессе изучения кода, благо open-source. Ещё один минус — слабые возможности парсинга. Например, Loki не умеет парсить multiline-логи. Также к недостаткам можно отнести то, что Loki — относительно молодая технология (релиз 1.0 был в ноябре 2019 года).
Заключение
Loki — на 100% интересная технология, которая подходит для небольших и средних проектов, позволяя решать множество задач агрегирования логов, поиска по логам, мониторинга и анализа логов.
Мы не используем Loki в Badoo, так как имеем ELK-стек, который нас устраивает и который за много лет оброс различными кастомными решениями. Для нас камнем преткновения является поиск по логам. Имея почти 100 Гб логов в день, нам важно уметь находить всё и чуть-чуть больше и делать это быстро. Для построения графиков и мониторинга мы используем другие решения, которые заточены под наши нужды и интегрированы между собой. У стека Loki есть ощутимые плюсы, но он не даст нам больше, чем у нас есть, и его преимущества точно не перекроют стоимость миграции.
И хотя после исследования стало понятно, что мы Loki использовать не можем, надеемся, что данный пост поможет вам в выборе.
Репозиторий с кодом, использованным в статье, находится тут.
Источник: https://github.com/black-rosary/loki-nginx
Was this helpful?
0 / 0