Prometheus server настраивается через два места: жопу и голову аргументы запуска и конфигурационный файл. Настройку через переменные окружения в Prometheus не завезли и не планируют.
- Как долго Prometheus должен хранить метрики
- Интервал опроса экспортеров и job name
- Как навесить дополнительных меток хостам
- Как убрать номер порта из таргетов
- Service discovery
Как долго Prometheus должен хранить метрики
Это зависит от того, как вы будете их использовать. В идеале надо иметь два набора метрик: краткосрочные на пару недель и долгосрочные на несколько месяцев. Первые нужны, чтобы оперативно отслеживать ситуацию, вторые — чтобы видеть тенденцию на больших промежутках времени. Но это большая тема, заслуживающая отдельной статьи, а пока сделаем по-простому. Длительность хранения метрик указывается в аргументах запуска Prometheus. Есть две опции:
--storage.tsdb.retention.time=... определяет как долго Prometheus будет хранить собранные метрики. Длительность указывается так же, как и в PromQL для диапазонного вектора: 30d — это 30 дней. По умолчанию метрики хранятся 15 дней, потом исчезают. К сожалению нельзя одни метрики хранить долго, а другие коротко, как, например, в Graphite. В Prometheus лимит общий для всех.
--storage.tsdb.retention.size=... определяет сколько дискового пространства Prometheus может использовать под метрики. По-моему эта опция удобнее предыдущей: можно указать всё свободное место на диске и получить настолько долгие метрики, насколько это возможно при любом их количестве. На практике однако нельзя указывать свободное место впритык. Дело в том, что у БД метрик есть журнал упреждающей записи (WAL), который в этом лимите не учитывается. Я не понял от чего зависит максимальный размер WAL, поэтому какие-то рекомендации по запасу не могу дать. У меня максимальный размер WAL был 8 ГБ.
Если вы устанавливали Prometheus по моей инструкции без докера, то аргументы запуска вам надо прописать в /etc/systemd/system/prometheus.service в параметре ExecStart, после чего выполнить две команды:
# systemctl daemon-reload
# systemctl restart prometheus
Если же Prometheus работает в докере, то надо внести изменения в docker-compose.yml и переподнять контейнер.
Интервал опроса экспортеров и job name
Давайте взглянем на минимальный конфиг из предыдущей статьи, чтобы вы понимали о чём идёт речь:/etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'node'
static_configs:
- targets:
- localhost:9100
- anotherhost:9100scrape_interval — периодичность опроса экспортеров (scrape дословно с английского — это соскабливать, соскребать). В отличие от длительности хранения метрик, может быть разной для разных метрик. Во всех мануалах я встречал цифру в 15 секунд, но почему-то никто не объяснял эту магическую константу. Почему не 2, 5 или 10? В целом так: чем меньше интервал, тем выше будет разрешение графиков и тем больше места потребуется для хранения метрик. Видимо 15 секунд — это золотая середина, найденная опытным путём.
job_name — имя (для Prometheus’а) для данной группы метрик. job_name будет светиться в интерфейсе Prometheus’а на вкладке Targets, а также попадёт в метку job для группы метрик c этих машин:
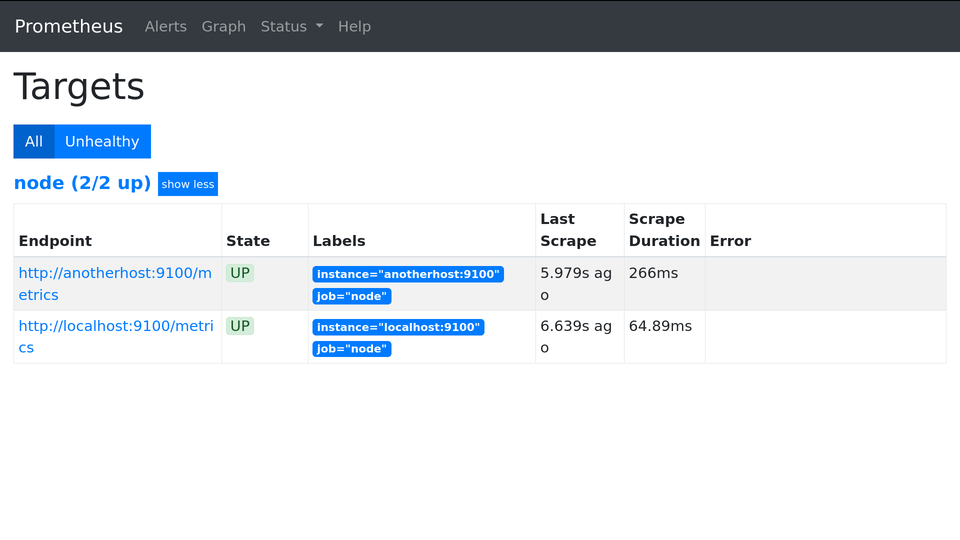
Как правильно подобрать имя для job_name ? Я пробовал разные варианты и в итоге остановился на простом правиле: называть job’ы в соответствии с экспортерами: node для node_exporter, cadvisor для cadvisor’а и т.д.
После редактирования конфига надо попросить Prometheus’а перечитать свой конфиг. Для этого надо послать ему сигнал SIGHUP одним из способов:
# systemctl reload prometheus
или
$ docker kill --signal=SIGHUP prometheus
Как навесить дополнительных меток хостам
Элементарно!/etc/prometheus/prometheus.yml
scrape_configs:
- job_name: 'node'
static_configs:
- targets:
- host-a:9100
- host-b:9100
labels:
project: 'boo'
env: 'prod'
- targets:
- host-c:9100
- host-d:9100
labels:
project: 'boo'
env: 'dev'Результат в интерфейсе Prometheus:
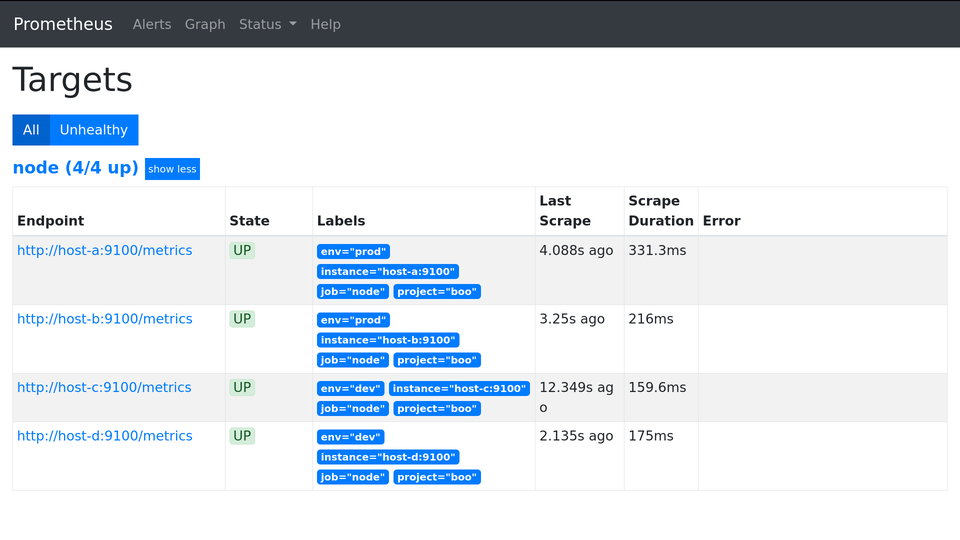
В запросах будет выглядеть так:
Expression: node_load1
node_load1{env="dev",instance="host-c:9100",job="node",project="boo"} 2.04
node_load1{env="dev",instance="host-d:9100",job="node",project="boo"} 0.8
node_load1{env="prod",instance="host-a:9100",job="node",project="boo"} 1.1
node_load1{env="prod",instance="host-b:9100",job="node",project="boo"} 1.5
Метки можно вешать любые на ваш вкус, не только project и env.
Как убрать номер порта из таргетов
Я не люблю лишнее. Вот зачем мне номер порта в метке instance? Какая от него польза? Он только сообщает, что node_exporter работает на порту 9100, но является ли эта информация полезной? Нет. Поэтому порт надо скрыть:/etc/prometheus/prometheus.yml
...
scrape_configs:
- job_name: 'node'
static_configs:
- targets:
- localhost:9100
- anotherhost:9100
metric_relabel_configs:
- source_labels: [instance]
regex: '(.*):9100'
replacement: '$1'
target_label: instanceПорт скроется не везде. На вкладке Targets он останется:
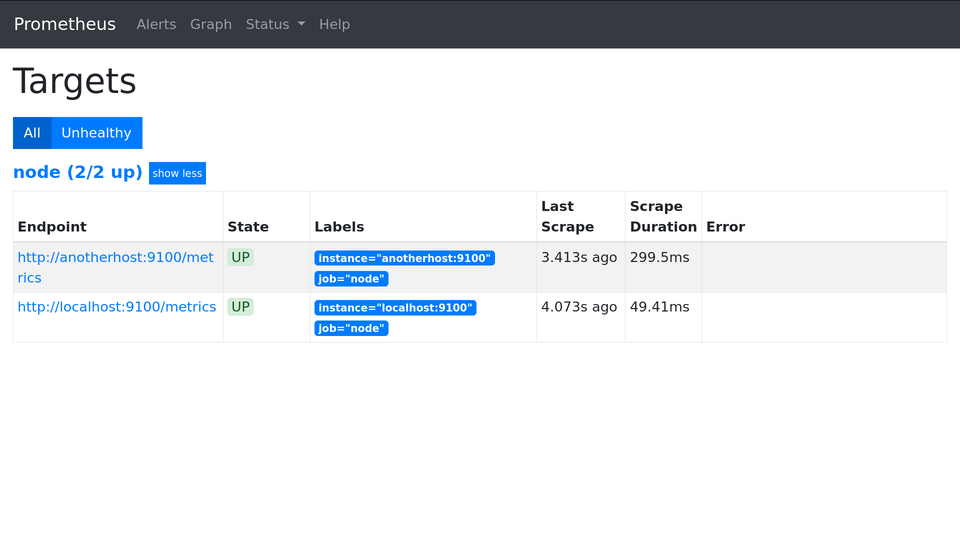
А в запросах исчезнет:
Expression: node_load1
1.67node_load1{instance="localhost",job="node"}
0.13node_load1{instance="anotherhost",job="node"}
Кроме одного:
Expression: up
1up{instance="localhost:9100",job="node"}
1up{instance="anotherhost:9100",job="node"}
Service discovery
Service discovery — это автоматическое обнаружение целей. Суть в том, что Prometheus будет получать список целей из какого-то внешнего источника: consul, openstack или что-то ещё. Service discovery — удобная штука, особенно если у вас инфраструктура развёрнута в облаке и машины регулярно рождаются и умирают.
Самый простой service discovery работает на файликах. В конфиге пишем так:/etc/prometheus/prometheus.yml
scrape_configs:
- job_name: "node"
file_sd_configs:
- files:
- /etc/prometheus/sd_files/*_nodeexporter.yml
refresh_interval: 1mPrometheus засунет в джобу node все таргеты из файлов, которые лежат в /etc/prometheus/sd_files/ и оканчиваются на _nodeexporter.yml. Всё это будет работать без перечитывания конфига.
Пример файла с таргетами:/etc/prometheus/sd_files/boo_nodeexporter.yml
- targets:
- 'host-a:9100'
- 'host-b:9100'
labels:
project: 'boo'
env: 'prod'
- targets:
- 'host-c:9100'
- 'host-d:9100'
labels:
project: 'boo'
env: 'dev'Удобно держать таргеты разных проектов в разных файлах. В моём примере лишь один проект с названием “boo”, остальные делаются по аналогии. Думаю разберётесь.
Чем отличается перечисление таргетов непосредственно в prometheus.yml от перечисления в отдельных файлах? В первом случае надо давать команду перечитывания конфига при редактировании, а во втором нет.
Источник: https://laurvas.ru/prometheus-p3/
Was this helpful?
0 / 0